天文学では常に見えないものを見ようと,新しい波長域の開拓,観測装置や解析方法の工夫を重ねてきた.そして,歴史ある可視域での観測に加えて,電波天文学,赤外線天文学,X線天文学等の発展が促されて,低温の星間ガス,高温の星間ガス,そ してガスから星,惑星の形成とその輪廻が解明されてきた.その一方で,宇宙の開闢直後の物理,その直後に起きたとされる銀河の形成,大規模構造の原因,さらに今後の宇宙の運命を定める宇宙の平均密度などについては分らない点が多い.これら現代天文学最前線の謎を解明するためには,従来のような観測装置の高感度化だけではなく,多くの天体の観測を行ってその統計的振る舞いを検討することが肝要である.特に,広い領域を均質に観測するサーベイは観測的宇宙論の進展にとって重要な鍵となる.
また,このような統計的扱いを行うと,性質が分っている天体とは異なる振る舞い を見せる天体データも数多く見えてくる.これらの「未知天体」は,多くの場合これ まで知られていなかった天体現象を反映しており,歴史を振り返ってみても天文学の発展のドライビングフォースとなってきた.
高感度かつ均質な観測データが取得可能な時代となった.広く見ることによって初めて見えてくる世界がある(cf. 宇宙の大規模構造).また,天体現象は一般に人間の生活時間に較べて非常にゆっくりとした変化しかしないので,様々な段階にある多くの天体の相互比較をすることにより,天体現象の正しい理解が可能となる.データの量が質に変化するのである.これを目指して天文学ではできるだけ多くのデータを取得しようと努力を重ねてきたのである.
一方,望遠鏡で観測する領域(波長方向も含めて)が広くなると,研究目的以外の天体も観測されることになる.多くの場合は,観測提案をした研究者はこれらの天体データの解析は行わない.しかしながら,他の研究者にとっては「せっかく取得した 観測データを活用したい」と思う研究対象であるかもしれないのである.即ち,残存 情報は不要なのではなく「宝の山」なのである.1.3で示したように,アーカイブを 利用した研究が近年激増していることからも,天文コミュニティとして「宝の山」を 共有したいという要望が強いことが理解されよう.
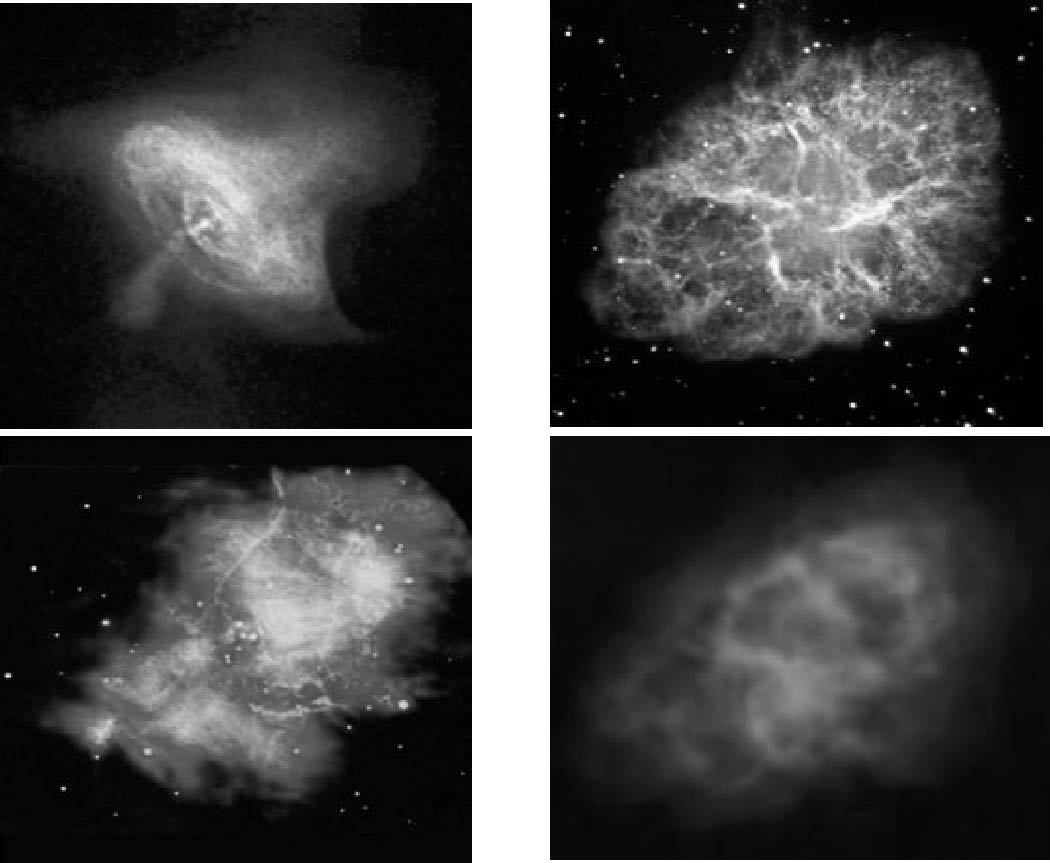
天体は一般的に広範囲な電磁波スペクトルを持つことは良く知られた事実である. 実際,恒星や銀河の研究では「色」によって表現される物理量を用いた様々な研究が 行われてきた.これから容易に類推できるように,広い波長帯域のデータを見ないと 天体の「正しい姿」が見えないのである.その例として図1にカニ星雲を様々な波長 で撮影した画像を示す.
天体物理学の歴史は,写真乾板以来,観測装置の高感度化や大型化を通して,できるだけ多くの観測データを取得しようニした歴史とも言える.これまでは増大したデータを,(1) ハードディスクやテープ装置の集積度が足りないために蓄積する場所の 確保に苦労,(2) 解析用計算機の能力(CPU速度やメモリ量)の制限のために大量の データ処理を行うために時間がかかりすぎた,(3) ネットワークの転送速度の制限に より大量のデータを輸送するためにはテープで送ることが主体,という状態であっ た.つまりその宝を取っておくだけの計算機資源が確保されないために,せっかくの 宝も死蔵されてしまう運命を辿っていた.
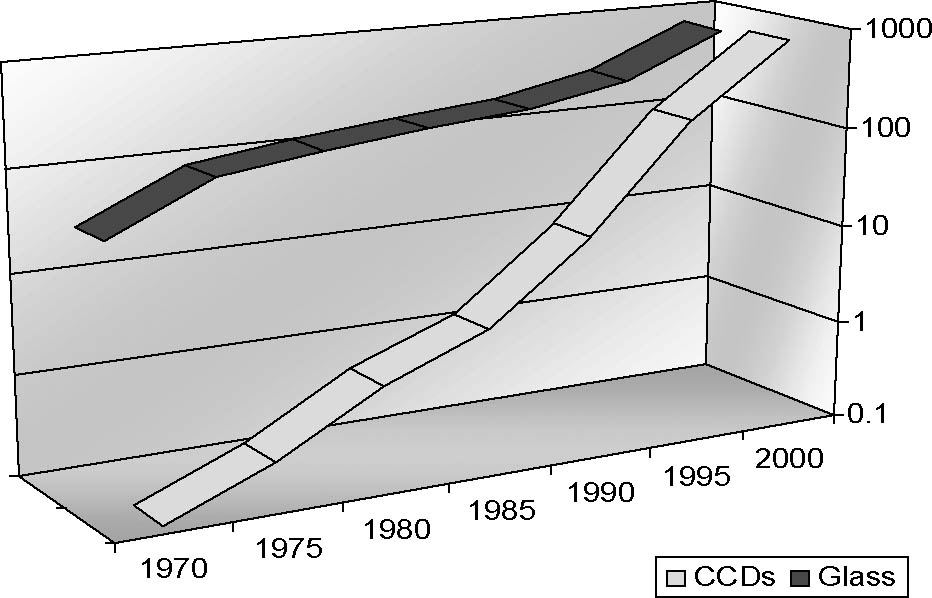
最近ではディジタル技術の導入により,観測データの巨大化は驚くべき速さで進ん でいる.半導体の稠密度の向上は,経験則であるMooreの法則「半導体の集積密度は 18ヶ月で倍増する」に沿って進んできた.その最新技術を用いた天体観測用検出器を 構成するCCD2次元素子は,すばる望遠鏡のSuprime-Camの場合,2k×4k (×10) とな っている.つい数年前はこのサイズのCCD素子は「最先端」であったものが,現在で は「普通」のものなのである(図2参照).この結果,生み出される観測データの規 模も巨大化し,先のSuprime-Camの場合,毎夜最大15 GByteにも達する.また現在国 立天文台が欧米と協同して建設を進めているALMA望遠鏡の場合,60台のアンテナから の相関データを超高速に処理するために,データ生産量は年間~PByte(1PByte = 1× 1015Byte)にも達する.
一方,このMooreの法則は計算機の心臓部であるCPUの性能向上についても成り立 つ.さらに最近のPCやワークステーションに接続するハードディスクやテープ装置の 容量の増加,低価格化には目を見張るものがある.即ち,半導体微細加工技術の発展 の結果,観測データの取得装置,蓄積装置,処理装置のいずれも急速に巨大化/高性 能化していることが分る.
一方,観測データを処理する際に最終判断を下す人間の能力には限界がある.人間の考え方や行動パターンは,過去の経験等に照らして決定されるため,大きな慣性を持つ.つまり,1.4に述べたようなデータ生産率の爆発的増大が生じるにも関わらず,従来通りのデータ処理を行おうとする.容易に理解できるように,従来通りのインタラクティブなデータ処理方法を取っていたのでは,「データを取得する時間よりも,データを処理する時間のほうが圧倒的にかかる」という事態に陥ってしまう.新世代望遠鏡による爆発的データ生産に対応するためには,人間の情報処理能力で対応できる量までデータをreduceしなければならない.そこで,従来の方法論とは異なるデータ処理方式を導入せざるを得ない.
わが国におけるネットワークの高速化は他国に較べて遅れている.しかし2002年初めには国立天文台も10Gbpsの速度を持つSuperSINETに接続され,それまでに較べて対外接続速度は1000倍にもなった.インターネットの帯域幅の拡大については,半導体の集積度の向上を示すMooreの法則に対応するNielsenの法則―ハイエンド・ユーザの接続速度は毎年50%増大する―で記述される.Nielsenの法則が示すネットワーク転送速度の急激な高速化(同時に低価格化)は,大量のデータの転送が極めて容易になること,また,遠隔地の計算機資源をあたかもlocalな計算機資源として利用することが容易になる可能性を示している.即ち,計算機利用に関するパラダイム転換が必然であることを意味している.
前節で述べたパラダイム転換のためには,ハードウエアとして利用可能な計算機資源の持つポテンシャルを十分に活用するための技術(ソフトウエア,ミドルウエア等)が必須である.情報学,計算機科学は最近の計算機性能の向上にも貢献すると同 時に,その利用技術の研究も進めている.
Webの導入がインターネット利用を学術目的から商用目的に拡大した事実は記憶に 新しい.Web上に散在する各種情報を自動的に収集してデータベース化する技術によ り,私たちはインターネット空間を,図書館代わりに利用することができるようにな った.これが,電子図書館や電子出版を進める原動力になったとも言える.ネットワ ーク(LAN)上に分散した計算機資源を透過的に利用するためのCORBA (Common Object Request Broker Architecture) 技術はすばる望遠鏡システムにも導入され, DASHシステムとして稼動を開始している.この考えをさらに広域ネットワークにも広 げたGRID技術が注目されている.遠隔地にあるスーパーコンピュータをGRIDで結合し て巨大スーパーコンピュータとして使おうというGrid Computing,遠隔地にある巨大 データ資源を透過的に使おうというData Gridの研究が世界的に拡がっている.例え ば,CERN(欧州加速器機構)における高エネルギー加速器実験であるATLAS計画の中 核を担うミドルウエアとして研究されているGriPhyNや英国の天文Data Gridである AstroGridなどがある.
さらにデータベース技術の研究においてもOODB(Object Oriented Data Base)技 術が開発され,これまで多用されていたRDB (Relational Data Base)よりもデータベ ース項目の拡張が容易であるという点から,利用が拡大している.また,これらを用 いたVLDB (Very Large Data Base) の構築においては毎年世界的規模の研究会が開催 されている.多量のデータの中から「重要な知見」を見出すための技術であるデータ マイニングも情報学における研究フロンティアの一つである.決定木(回帰木)法, ニューラルネット法,Memory-Based Reasoning法など,様々な手法が研究・開発され ており,これらをビジネスに応用している例も多い.
さて観測の手順を思い起こしてみる.「実観測」は計算機コンソールに向かって, 観測天体の座標,観測装置の設定パラメータ,開始時間などを入力して実行する.装 置が取得したデータはモニターなどで監視でき,観測が正常に終了すると,ヘッダの ついた観測データファイルが(観測データベースシステムを経由して)解析用計算機 に送られる.研究者はこれを解析して論文とする.
一方「データベース観測」も計算機コンソールに向かって,観測天体の座標,観測 装置の設定パラメータ,などの検索パラメータを入力してDB検索を実行する.データ アーカイブから取得したデータは早見画像などで大雑把なチェックができ,検索が正 常に終了すると,ヘッダのついた観測データファイルが(検索データベースシステム を経由して)解析用計算機に送られる.研究者はこれを解析して論文とする.
この手順を思い起こしてみれば,「実観測」でも「データベース観測」でも得られ るデータは本質的には変わらない.そして,「DB/DA」,「解析計算機」は必ずしも 研究者の手元にある必要はなく,高速ネットワークを通じて遠隔地にあるものを利用 することで十分である.つまり,「データベース観測」の場合は,高速ネットワーク に接続された研究室の端末が先に述べた「コンソール」となり,様々な命令を入力す ることで「観測」が可能となるのである.言い換えると,これは高速ネットワーク上 に建設された「仮想望遠鏡」―Virtual Observatory(VO)―を利用することに等し く,観測そのものをこのように抽象化することができるのである.
「実観測」の場合,これまでに観測が行われていないデータを望遠鏡で取得すると 考えることもできる.「データベース観測」の場合にVOにデータがない場合は,自動 的に観測手順(実望遠鏡の操作命令列)を生成してVOが「実観測」を行えばよい.研 究者は,研究目的をクリアにしたプロポーザルを作成し,それに対応するデータを得 ればよいのである.
世界では欧米を中心として,仮想観測所「建設」計画が進みだしている.ここでは 代表的なものとして米国のNVO (National Virtual Observatory) とESOのAVO (Astrophysical Virtual Observatory) について概観する.他にも,英国の AstroGrid,オーストラリアのAVO (Australian Virtual Observatory) 計画などがあ る.
NVOはCalifornia工科大学やJohns Hopkins大学が中心となり,米国が設置してきた データセンター(HEASARC,IPAC,STScIなど),スパコンセンター(イリノイ,サン ディエゴ),文献サービス(ADS,NEDなど),データ解析ソフトウエア(IRAF,AIPS,AIPS++など)を高速ネットワークで結合し,観測データ検索や計算サービスを提供することにより他波長の数値宇宙を構築し新しい天文学の研究スタイルを構築しようとするものである.NVOは天文学者のみならず計算機科学研究者と協同で開発することとなっており,2001年にNSFはNVOに5年にわたった1000万ドルの予算をつけた.
AVOはESOとESAが中心となってVLT(ESO),ISO,ST-ECF (ESA),SIMBAD等のカタログ DB (CDS),CFHT+MEGACAM (TEREPIX),及びMERLIN (Jodrell Bank) を高速ネットワークで結合するためのインフラストラクチャーを構築し,観測データの再利用をするだけでなく多波長,多観測装置データの比較処理を行うことを通じて新たな天文学的知見を見出そうというものである.AVOの特徴としては,この「仮想望遠鏡」に対するプロポーザルを公募することにより,焦点が絞られた研究をバックアップしようという点,また,天文データセンターの重要拠点であるCDSが参加しているのでカタログデータベースが充実している点が挙げられる.EUはAVOに400万Euroの予算をつける ことを決定している.
ALMA望遠鏡は,日米欧共同でチリ・アタカマ高原に建設するミリ波サブミリ波の大型干渉計である.そのデータ生産量は年間~PByteにも及ぶ.観測データはチリから日米欧に配信され,3ヵ所のRSC (Regional Support Center) を経由して研究者が利用 することとなる.そして,米国のRSC,欧州のRSCもそれぞれの地域で構築を進めてい るVO (NVO,AVO) に接続していくことを前提に,RSCの機能設計を進めている.
日本にもALMA-JのRSCを設置することとなるが,欧米との接続性を考えると,ALMA-J RSCも日本版VO (JVO) に接続することを前提として設計を進めることになろう.JVOには,国立天文台のすばる望遠鏡の観測データが接続され,また,国立天文台が計画しているアストロメトリ計画であるJASMINEチームもJVOに接続することを希望している.このことは,JVOが保有する数値宇宙に「非常に精度の高い reference frame」を与えることが可能になるという,他のVOには見られない特徴を与えることを意味する.
JVOでは,様々な望遠鏡や観測装置で取得した観測データを統一的に扱う.このためには,分散して存在するDB(それぞれのデータフォーマットは異なる)への検索方式や検索結果の表示法の共通化,及び,各DBからVOにデータを読み込む際に,コンバーターを通してVO内部での標準データフォーマットにそろえる必要がある.また,解析プログラムのデータ入出力方法の共通化が必要となる.
VOに取り込まれた観測データは,OODB (Object Oriented Data Base) の機能により論理的に結合されてディジタル宇宙(数値宇宙)の構成要素となる.観測的宇宙論や銀河形成など統計的手法を用いる研究には稠密な数値宇宙を構築することが望ましく,サーベイ観測データが中心となる.また狭視野の観測装置によるポインティング観測データもVOに取り込む機能が必要である.数値宇宙の構成要素となる観測データ は,その質が保証されていなければ科学的研究に使用することが困難である.そのため観測データの質を示す指標をDB情報の一つとして保持する機能が必須である.
先の数値宇宙に対し多様な検索キーで検索する:座標(赤経・赤緯の各元期,銀経・銀緯),波長(周波数),観測時期,など.また一歩進めて,例えば「似た特徴を持つ天体」を探させるには2.4の機能を応用すれば可能となろう.ユーザーは(例えば)画像を指定し,それからVOが検索キーを自動生成するというのも面白いであろう.
同じ視野の異なる観測時期のデータを比較するなど多様な画像処理,天体の自動認識・自動抽出およびそのパラメータ抽出とカタログ生成,空間分解能を考慮したクロスマッチ等と統計処理,wavelet,curvelet,ridgelet等を用いた天体の特徴抽出,カタログを参照しつつ未測定のパラメータを追加する機能,各種プロット機能,カタログや測定パラメータのモデルフィッティング,等.
検索や解析を行った結果は基本的に多次元空間に分布する物理量パラメータの組であるため,これを可視化することで研究者による結果解釈をしやすくする機能.これは,人間が持つ高度な画像認識能力をうまく活用(Visual Data-mining)して研究成果を挙げるために必須な機能であると考えられる.2D,3Dプロット(軸はユーザー指定),あるいは,可視化画像の自由な回転などもできることが求められる.アニメーション化や,あるいは,カラーと半透明表示をうまく用いた4Dプロットも有効であろう.
データマイニング技術を活用することにより,多次元パラメータ空間の特徴抽出,クラスタリング,分類,パラメータ間の相関ルール抽出,等を可能にする.これを活用することにより,例えば,大量の銀河データのなかから自動的にこれまでの分類に当てはめると同時に,当てはまらない「未知天体」を探し出すことが可能になる.
これまでに述べたVOに必要な機能を実現する際には,観測所が観測データの一次較 正まで行ってデータの質を保証し,観測DBに登録しておくことが必須である.VOの利 用者は,様々な観測装置の詳細を知らないと考えるべきであり,VOに取り込まれたデ ータから装置の特性を除去することを各利用者が行うことは期待できない.従って, 「観測データの一次較正を行ったデータのデータベース化」までが観測所の責任で, それ以降はVO側の責任であると,明確に切り分けることで,観測所とVOの連携を行 う.
VOは成長するDBシステムと捉えることもでき,また,天候に左右されずにいつでもどこからでも「観測できる」ことが特徴である.従って,高い拡張性能,容易な保守性能,セキュリティも含めた高い安定性が必要とされる.そのためには分散処理(GRID)及びデータベース(Object Oriented Data Base)技術を活用しなくてはならない.
1.7でも述べたが,GRID技術はネbトワーク上に分散した計算資源を結合し,活用するための基盤ミドルウエアとして注目されている.CERNではGRID技術を用いて加速器データを世界中に配信することを考えており,国内では高エネルギー加速器機構と産業技術総合研究所がALTASのGriPhyN計画の国内窓口となっている.また,SuperSINETを活用して遠隔地のスーパーコンピュータを連携運転させる(Grid Computing)ための基盤技術としても用いられることとなっている.
Globusには,遠隔地の計算機資源を用いるための,計算資源管理ツール,ローカルな認証を行うことで登録された遠隔地の計算機資源を利用できるようにするための認証サービス,セキュリティ機能などが搭載されているため,VOを構築するためには最適のミドルウエアである.また,このツールを用いて既存の解析ソフト等をラップすることにより,容易に新しいソフトウエアを追加できる.さらにネットワーク上のあるマシンが停止しても,計算機資源管理ツールによって他の同等の機能を持つマシンを自動的に選択することができるので利用者はどのマシンが使えるかを気にすることなくVOを利用することが可能となる.
VOでは基本的に大量のデータを客観的に取り扱う.このためにはパイプラインによる自動処理が必要となる.パイプラインには,数値宇宙を観測する望遠鏡としての検索と観測装置としてのデータ解析(パラメータ測定やカタログ作成等)の2種類がある.また,データ解析処理ソフトを自由に組み合わせてデータ解析パイプラインを作るためのパイプラインビルダーの機能も必要である.
さて,Gridを用いることにより,従来のように「観測データを解析マシンのハードディスクに落とす」必要がなくなる.JVOではネットワーク上で移動するのは観測データだけではなく,解析プログラムとその結果も移動可能である.例えばSuperSINET等の高速ネットワークを用いても数10 GByteのデータを転送するためには,それなりの時間がかかってしまうし,転送したデータをローカルに蓄積しなければならないという従来からの問題に遭遇する.JVOではネットワーク上を移動するのは,基本的には,はるかにサイズが小さい解析プログラムとその結果である.もちろん,JVOでは従来のように,分散DBから必要な観測データを特定の計算機に移し,その特定の計算機上でしか動作しない解析プログラムを用いることも可能である.この場合でも,解析結果はネットワークを通してユーザーターミナル上で表示させることができる.
サーベイ観測ではdata qualityを保証する観測を行うことが必須である.将来VOを 通じて「全ての観測」を行う時代になれば,VOが適切な観測手法や観測時間を自動的に指定することにより観測データの質を保証する.ユーザーは観測時間を指定する必要がなくなる.
既存解析ソフトの組み込み利用,自作解析モジュールの組み込みを容易にするために,globus tool kitによって構成される標準入出力モジュールや解析ソフトを自作するための「雛型」を提供する.自作モジュールが有用でかつ不特定多数の利用に耐えるだけのエラー処理等を組み込んであれば,これをシステムに登録して広く利用できるようにする.
数値宇宙を観測し,新しく物理パラメータを測定して得られるカタログは多次元パラメータリストである.このパラメータ間の相関や分類にはn次元パラメータ空間の2次元/3次元投影による可視化が有効である.立体視によってパラメータ空間中に入り込みクラスタリングの状態など人間の空間認識能力を生かして調べることができる可視化のための装置としてデータcaveの利用が考えられる.
JVOはこれまでの望遠鏡システム構築の流れの自然な延長の上に成り立つ構想である.1.8にも述べているようにJVOでは,「検索できない場合はVOが観測手順書を用意して,実観測システムに観測要求を出す」ことまで構想している,天文学者が主導するVOシステムである.これは単一組織内に多波長に渡る世界レベルの観測装置を持つ国立天文台でなければできない計画であり,天文学者が情報学研究者と共同し衛星DBの統合化から始まった米国のNVOや実効的な小プロジェクトの集積からなる欧州のAVOは,そこまで踏み込んだ計画とはなっていない.即ち,JVOでは将来的にはVOが全ての観測のインターフェースとなり,観測という概念そのものを大きく変えることすら想定しているのである.
Construction of the Japanese Virtual Observatory (JVO)
Masatoshi Ohishi
National Astronomical Observatory of Japan
Abstract: The Japanese Virtual Observatory project has been launched. This article briefly describes the basic concept of the JVO. By using the GRID technology, JVO connects several observational data bases which are located in remote places in the world, and connects many computational facilities for data analyses and statistical analyses, via high speed networks. JVO could be one of a very good examples which applies the GRID technology in Japan. See, http://jvo.nao.ac.jp/ for more details.
図1 カニ星雲の画像 (左上)X線,(右上)可視光(左下)赤外,(右下)電波
図2 CCD素子の発展と望遠鏡集光力の増大
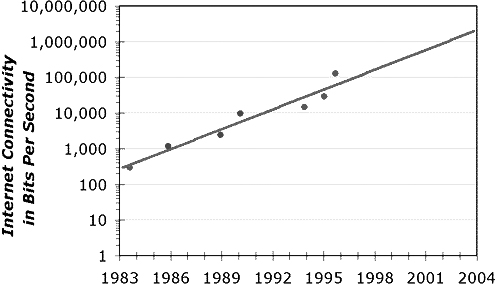
図3 Nielsenの法則.横軸は年(西暦)である.
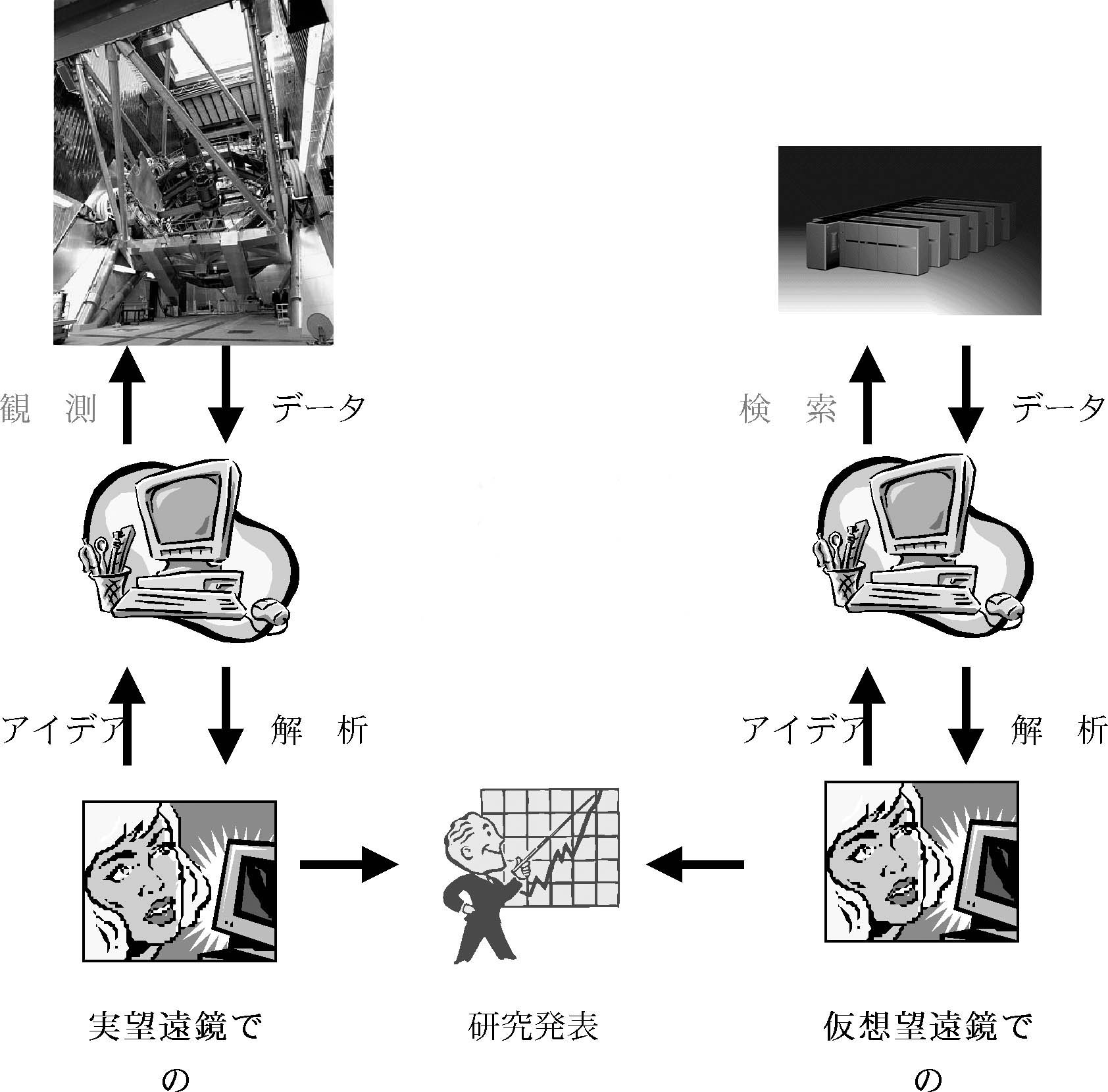
図4 実望遠鏡と仮想望遠鏡による観測の比較.「観測」と「検索」だけが異なる.
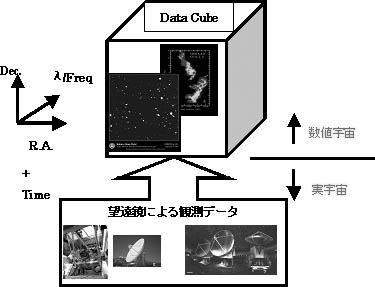
図5 ディジタル宇宙(数値宇宙)の概念
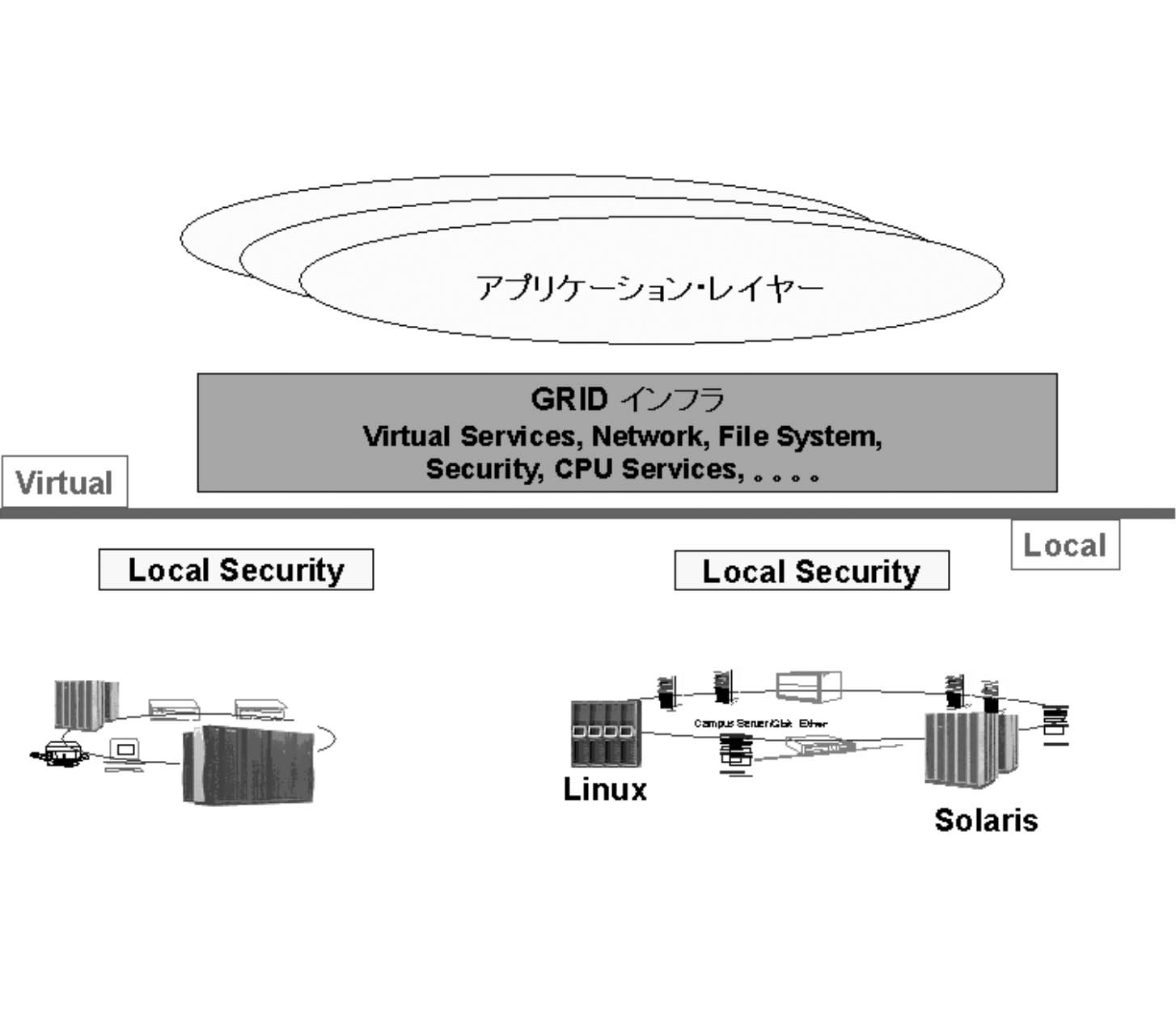
図6 GRIDを利用した遠隔地計算機の結合概念
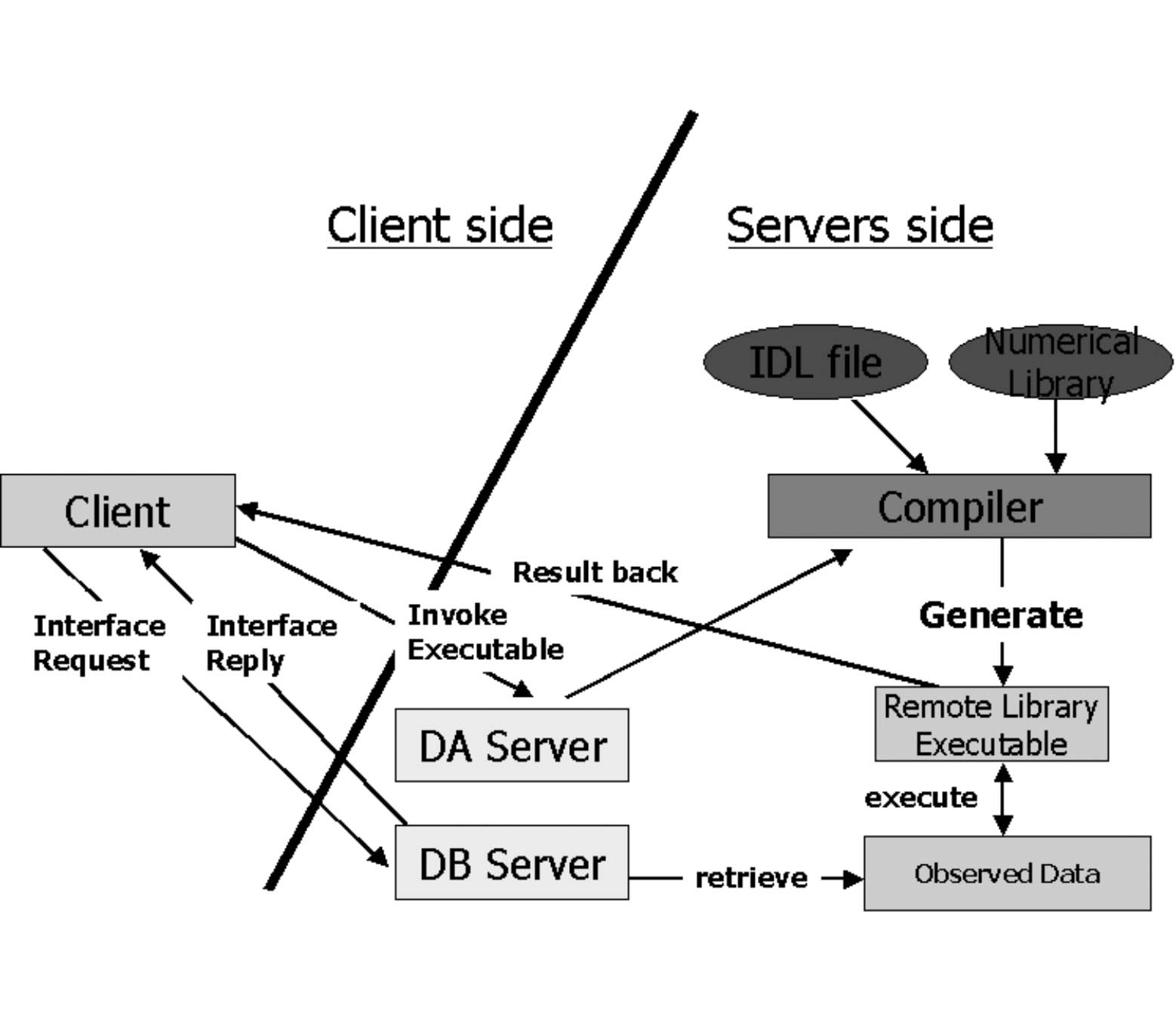
図7 GRID上における遠隔解析のイメージ